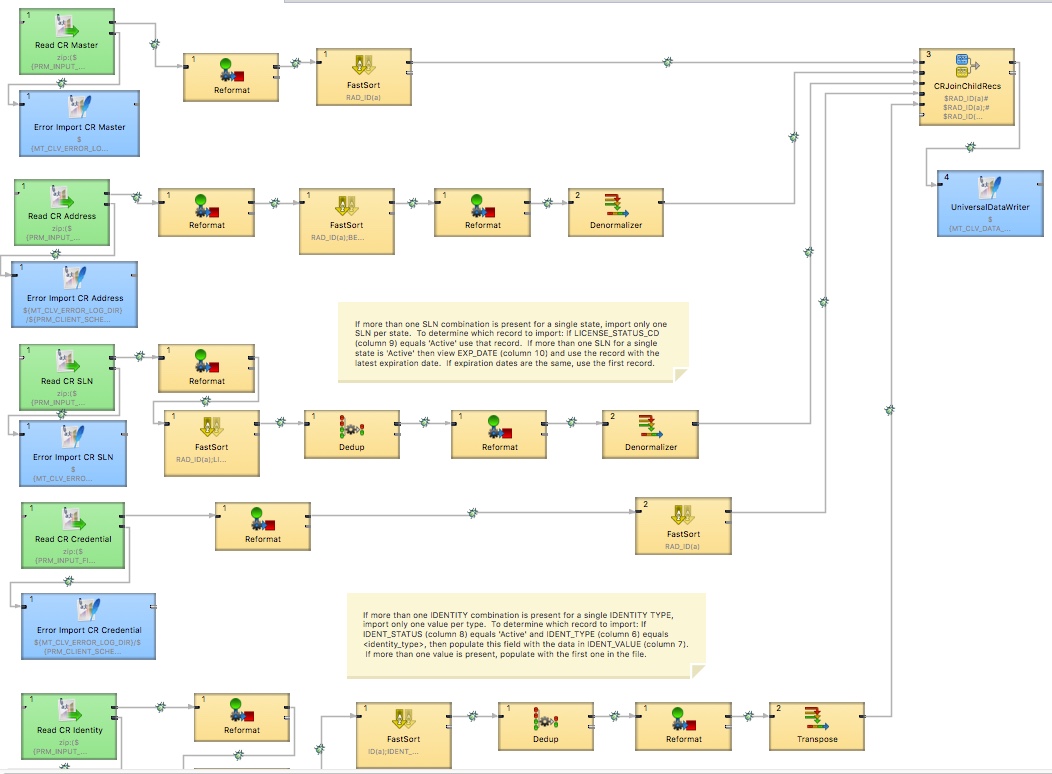
I have a graph that contains 5 flat file reader components reading files contained with a zip file passed as a parameter to the graph. For example:
Zip File Name: 20170628_medispend_customer.zip
url syntax for each reader:
zip:(${PRM_INPUT_FILE})#dim_cust_dly_???.dat
zip:(${PRM_INPUT_FILE})#dim_cust_addr_dly_???.dat
zip:(${PRM_INPUT_FILE})#dim_sln_???.dat
zip:(${PRM_INPUT_FILE})#dim_credential_???.dat
zip:(${PRM_INPUT_FILE})#dim_ident_???.dat
I have run the process successfully with a few different zip files.
A zip file (20170628_medispend_customer.zip) of size 19.7MB runs successfully.
A zip file (201700905_medispend_customer.zip) of size 15.2MB fails with error:
“Realocation of CloverBuffer failed. Requested capacity is 33554434 and maximum capacity is 33554432. java.nio.BufferOverflowException”
It fails when it tries to read zip:(${PRM_INPUT_FILE})#dim_cust_addr_dly_???.dat which is 27.6MB unzipped. The same file was 27MB unzipped for the process that ran successfully (20170628_medispend_customer.zip).
I have read some of your documentation regarding changing configuration settings for the clover engine when this sort of error occurs, but I am wondering why this would be necessary when the zip source file in question is smaller and the specific data file within the zip does not seem to be all that much larger than the similar file that ran successfully.
Can you shed some light on this? I am attaching a screen shot of my graph for you.
If it is in fact necessary, for whatever reason you provide, to change the configuration settings, can you provide the exact settings and values for them that would need to be configured on our CloverETL Server for the given use case?
I am also providing the log files for both the successful run and unsuccessful run of the same jobflow.
Thanks,
Heather
{kind=link}