A little background about what I am trying to accomplish in a certain portion of my graph (we are on 4.4.0.11):
I have multiple URLs that each downloads a zipped data file. I am passing the URLs to the HTTPConnector component which I am then passing the content to a UniversalDataWriter to be written to an S3 bucket. The files can vary in size, but the largest I have seen is 69MB. I have many of these URLs so I will be writing many larger data files to S3.
I get the following error at the HTTPConnector component:
Component [HTTPConnector:HTTPCONNECTOR2] finished with status ERROR. (In0: 2 recs, Out0: 1 recs)
Realocation of CloverBuffer failed. Requested capacity is 47041816 and maximum capacity is 33554432.
java.nio.BufferOverflowException
I have read about changing the RECORD_LIMIT_SIZE and changing Edge Types so I tried a few things:
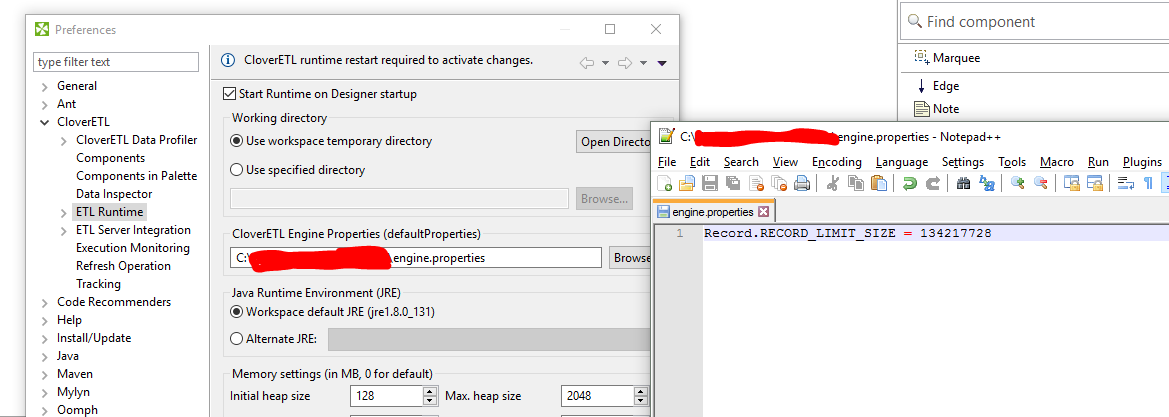
1. I followed the example in Chapter 17. Engine Configuration in the docs and made a copy of the defaultProperties file, changed the Record.RECORD_LIMIT_SIZE to 134217728, saved the file in the main Sandbox directory of my project, and pointed the Preferences > CloverETL > ETL Runtime > CloverETL Engine Properties (defaultProperties) to the new file. I then restarted the CloverETL Runtime of my Designer.
…a. When I run the graph I get the above error when running the graph.
2. I then changed the Edge Type from the HTTPConnector to the Trash component (I am using Trash to test this for now, but it will be the UniversalDataWriter to S3) to use the Edge Type Direct Fast Propagate.
…a. When I run the graph I get the above error when running the graph.
3. I switched the Edge Type back to Detect Default and went back into the defaultProperties and changed the Record.FIELD_LIMIT_SIZE to 100663296 (3x the default). I then restarted the CloverETL Runtime of my Designer.
…a. When I run the graph I still get the above error when running the graph.
4. I again changed the Edge Type from the HTTPConnector to the Trash component to use the Edge Type Direct Fast Propagate.
…a. When I run the graph I get the above error when running the graph.
It look as though it is either not recognizing the custom defaultProperties I have set or I am still not configuring this properly. The server defaultProperties have not changed since I did not make the change. I wanted to first try to override them with my defaultProperties file. Any guidance would be greatly appreciated!
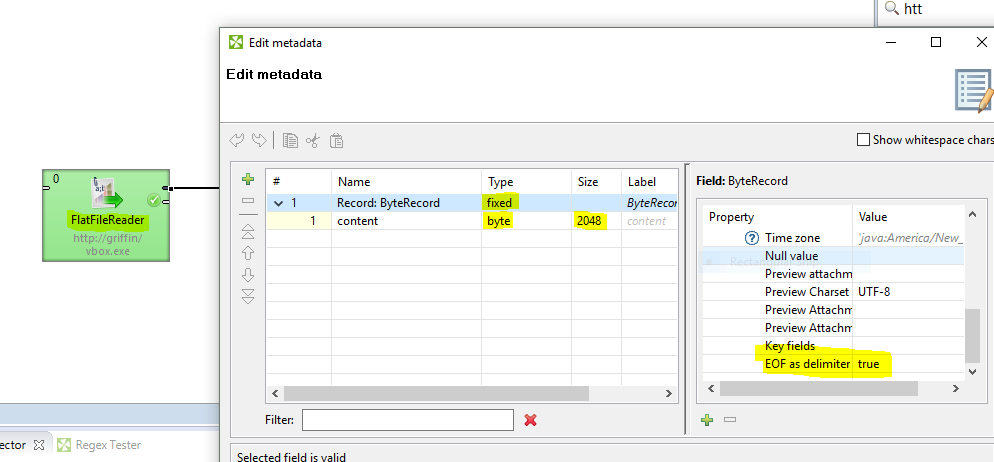
Well your first solution should’ve worked. I just tried to download 120 MB using following configuration: ffr_http_read.PNG
There is also solution I’d prefer when dealing with this kind of use case - read it directly using FlatFileReader. Case below illustrates how you can use FlatFileReader to download any binary data using supported protocols. This has the advantage, read is done in stream and therefore is not that memory consuming: http_connector_settings.PNG
So one thing that did help is that we did not have the metadata set correctly which I have since changed and that helped the graph make more forward progress than it did before. However, I still have files that one file alone is larger than the RECORD_LIMIT_SIZE. Based on your screenshots and aside from my file having the title “defaultProperties” and yours as “engine.properties” everything else looks the same, but it still does not look to be overwriting the default properties on the server at graph run time.
I have since made the change on the server for the RECORD_LIMIT_SIZE which helped once again for my graph to make it even further down the pipeline. However, I am now running into a new error:
Component [HTTPConnector:HTTPCONNECTOR8] finished with status ERROR. (In0: 2 recs, Out0: 1 recs)
Java heap space
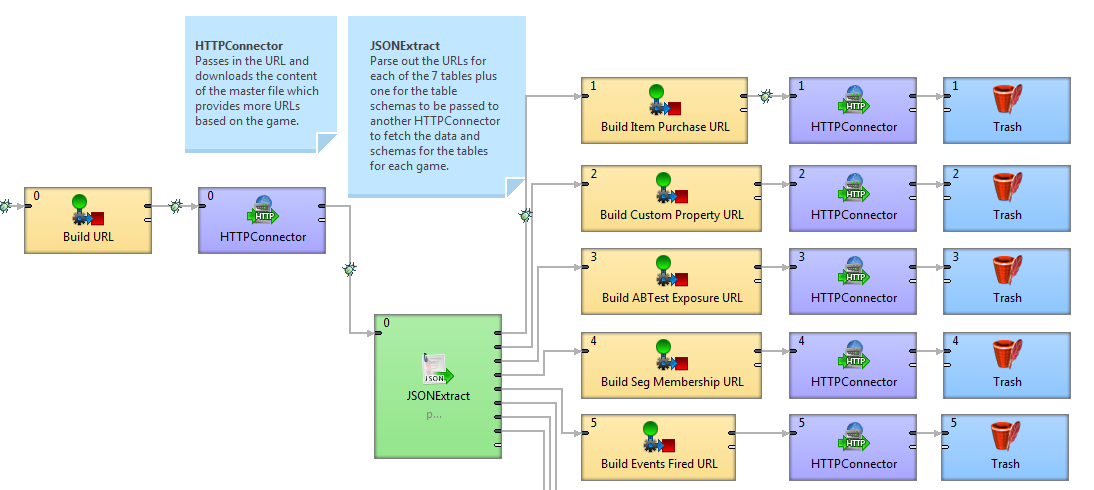
Here is an image of some of my graph so you have an idea of how it is setup: Graph.PNG
So if I understand correctly, you’re running those graphs on the server? In such a case (given you’re using Tomcat installation), change path to engine properties file in: /bin/setenv.sh (or .bat) as described here: http://doc.cloveretl.com/documentation/UserGuide/topic/com.cloveretl.gui.docs/docs/cloveretl-default-settings.html. Contents would be the same as illustrated in my previous post. These files won’t differ in any way between server and designer.
This error message is given by the fact, HTTPConnector actually stores the response in memory and if you do not have sufficiently sized Heap (parameters -Xms and -Xmx in setenv file of your Tomcat server), you’ll get this error. If we’d be talking about designer, just change values in boxes for Initial heap size and/or Max. heap size of the same dialog where you set the defaultProperties file.
For other server’s you mind need to inspects its documentation how to change Heap/change Java runtime parameters.
I ran the graph in my designer in a Server sandbox as well as on my designer not on the server. This will ultimately be on the server. I’m not sure the link you gave was the correct one? Did you mean http://doc.cloveretl.com/documentation/ … omcat.html
Does the HTTPConnector hold things in memory until the component is complete or the graph is complete? I have one game where all of the data files across the 7 HTTPConnectors will total around 4560 MB. I will be passing multiple games through, none of which should be as large as this one, but some may get up there. I’m trying to figure out if I need to size the Java heap for the whole lot or the max of what a component may get. Depending on the answer another question may be do I need to use a different approach/components to handle this sort of request?
No, link I sent is correct. Actually the most important part is the -Dclover.engine.config.file=/full/path/to/file.properties and the actual property which should be set in that file, i.e. Record.RECORD_LIMIT_SIZE. The first snippet specifies which attribute needs to be passed to the java process (in setenv file), the second which attribute needs to be set.
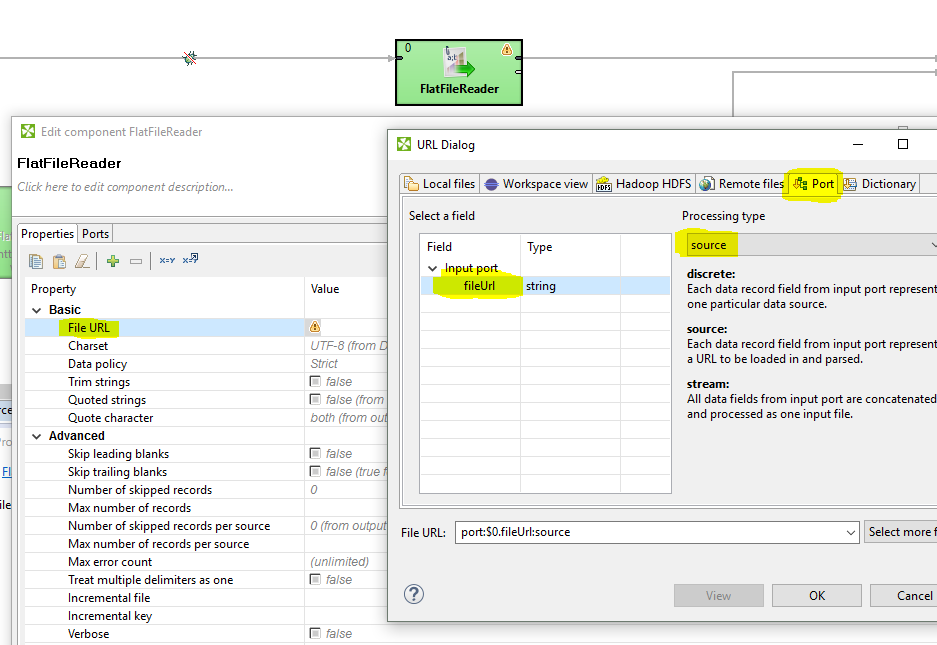
Well, that is a good question. Technically, the component processes one request after another. But how much data you have in the pipeline is a very different thing. So answer to that would be “somewhere in between”. Still, my recommendation would be either use JSONExtract directly (specify website as File URL attribute) or use FlatFileReader to download binary data and process them afterwards. May give you some performance boost since this way, you can actually utilize multiple readers in parallel without worrying about the memory that much.
So we increased the Java heap space on the server to 2 GB and that did not work. We are on a 32 bit machine so I’m not sure it would be smart to increase that any further.
I’m not sure I can use the FlatFileReader for what I would like to accomplish. I extract the URLs from the downloaded JSON since the URLs are not known ahead of time, then I parse them out and pass them through one by one to the HTTPConnector along with some other metadata information that will be used to dynamically tell clover which S3 directory a particular files needs to go to since they will not land in the same location. Unless there is some way to configure the FlatFileReader to do that which I am currently unaware of.
Well, if your files are on S3 datastore, then you might have it really simple. Because you can construct an S3 URL and pass it to whatever reader you need to use. So for example, that could be XMLExtract if file you have on your S3 is a zipped XML file.
The files are not already in S3, my goal is to get them into S3. This is the root of the problem I am having: being able to download the files from API URLs and get them into multiple S3 locations. Also, the directory in S3 does not exist ahead of time. This is why along with the large files I am downloading with the URL I am also passing additional information in the metadata such as Game Name, File Name, and Date in order to build an AWS CLI command to put the files in their respective directories.
I have built other solutions that do just this, but the files are much larger for this particular project so I am unsure of how to get Clover to work in this scenario. I usually download the file to a Clover sandbox directory temporarily, then call dynamic AWS CLI commands that are executed with an ExecuteScript component, then clean up the files on Clover after. This is why I am unfamiliar with the Reader/Writer component capabilities when it comes to dynamic S3 locations and files.
That should with small modification work if I understand it correctly. I stitched together a graph with some notes to better understand. Hopefully reflects your situation accurately, if not, let’s talk about more context in terms of where and how those files can be downloaded, if they are on a secured page, if some payload is necessary to send along request etc…
So the metadata that I want to pass through does not come from the URL Response. The metadata is passed in with the URL at the output of the “Build URL” component into the HTTPConnector. So the metadata coming from the Build URL component would look something like:
URL
api_key
game_name
file_date
file_name (This is different than the file name that is given when downloaded. We would like to rename.)
And the output metadata from the HTTPConnector would be:
content
api_key
game_name
file_date
file_name
I can then use this information to take that content, build the S3 location with the game_name, file_date, and file_name, and use a component to move and rename that file to the specified location.
I think in your example the additional metadata comes from the URL Response.
I’m not sure how the components access the lookup table after it has been created in your example. It doesn’t look like you are using it for the FlatFileWriter.
I cannot attach the call_id to the end of the URL because it doesn’t recognize it as a valid URL when I try to pass it. Also, is your example missing a LookupJoin component in order to get the values from the lookup table?
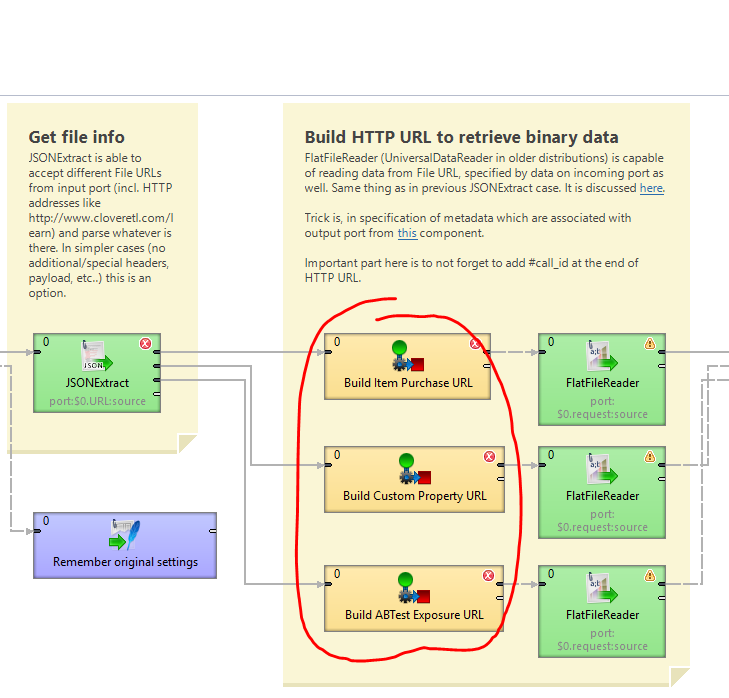
Alright, that may complicate things a tiny bit, but that’s not necessarily a problem. To have more elegant solution, I’d probably need to know what exactly is happening in these: url_prep.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}