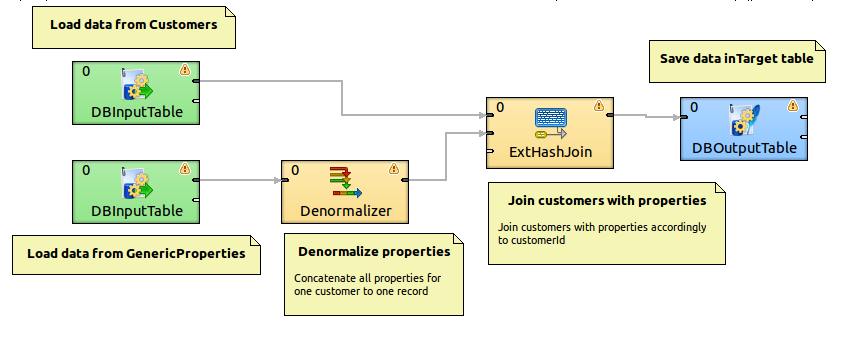
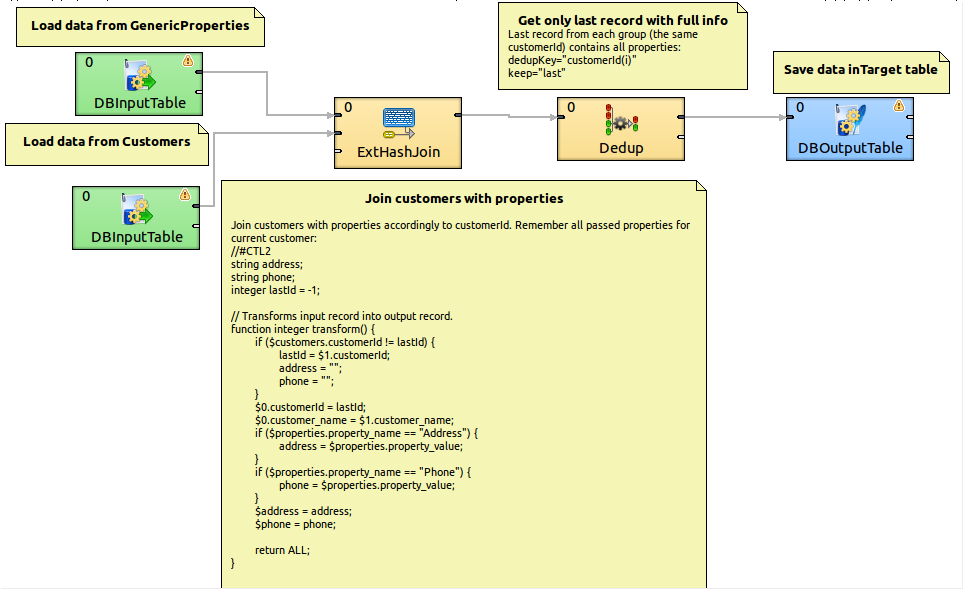
I am evaluating Clover ETL and can’t seem to find whether or not the following operation is possible. I don’t really care if this is a “custom” style operation, as long as the tool can actually do this:
Let’s say I have two tables in my source database. The first is a “regular” table, say “Customers”, with a primary key of “CustomerId”:
Source Table 1: Customers (
int customerId;
varchar customer_name;
etc.)
Table 1 Data:
CustomerId, Customer_name
1, Dell
2, IBM
Table two is the hard part: it’s a “properties”-style table, that has a link to the Customers table via it’s primary key (CustomerId), but each ROW contains a value that needs to go into a COLUMN on the target:
Source Table 2: GenericProperties (
int recordId; ← joins to CustomerId
varchar property_name;
varchar property_value;)
Table 2 Data:
recordId, property_name, property_value
1, Address, 1234 Main St.
1, Phone, 888-123-567
2, Address, 9911 Some Ave.
2, Phone, 877-456-7890
The Target table customer table:
Target Table: TargetCustomer (
int customerId;
varchar customer_name;
varchar address;
varchar phone;)
Desired result for Target table:
customerId, customer_name, address, phone
1, Dell, 1234 Main St, 888-123-567
2, IBM, 9911 Some Ave, 877-456-7890
Please note that the target table has as many rows as the source Customer table, which is twice as small as the Source GenericProperties table.
Is this possible with cloverETL?
{kind=link}
{kind=link}