I just begin to use CloverETL, but I already know Cloud Connect for GoodData for a while.
I have a doubt about incremental data load.
In Cloud Connect there was an option, in GD Dataset Writer component, where I could choose if append or replace all data. (please, take a look at print screen attached).
In CloverETL, I’m using MSSQLDataWriter. There is something like this in here? How can I choose if I’ll append or replace the data in SQL Server?
Thank you for your help. I started to use DBOutputTabl, but I still have some doubts.
I’m workig with a dimension, and I only want to insert new data (comparing to a key).
For example, at my Stage:
Key | F1 | F2
1 | x | y
Then, I execute my graph and copy that to my DW.
At a second moment, I will load my Stage again. And now, my Stage is like this:
Key | F1 | F2
1 | x | y
2 | x2 | y2
So, I only want to add the second row (with Key=2).
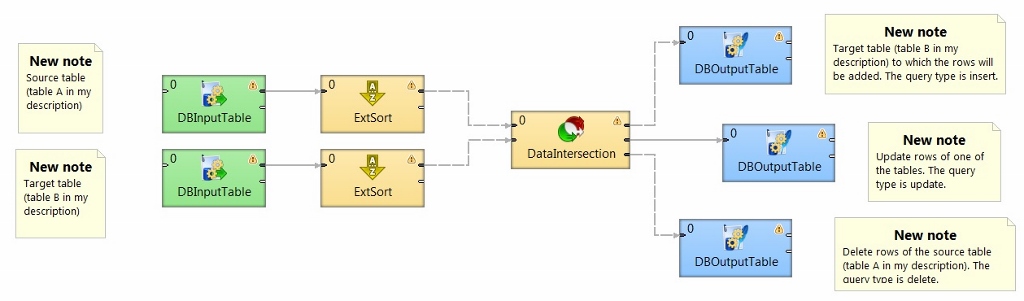
You can do this by implementing the component DataIntersection into your current graph. This component will compare keys from both tables, perform the user-defined transformation and send the data on one of three output ports. Selection of the output port depends on a comparison result of the keys from both tables. For more information please refer to the manual.
Now let’s focus on your example. As I understood, you would like to compare data from two tables and add the rows from one to the other when the keys do not match. To not run into much details I rather made a graph on which you can see how this can be implemented.
The data from both tables are sorted and sent on the input ports of the DataIntersection.
Dataintersection will compare keys from both tables.
Based on the input records, data will be distributed followingly:
a) If some of the keys of the table A are different from the keys of the table B, then the rows with the keys that are only in the table B are sent on the output port 0.
b) If some of the keys of the table B are different from the keys of the table A, then the rows with the keys that are only in the table A are sent on the output port 2.
c) If the the keys from both tables match, then the user-defined transformation is performed and the data are send on the output port 1.
Both ports 0 and 2 are connected to a write component to write the data.
Connecting a write component to the output port 1 is useful when is updating the content of one table with the other is desired.
Hello, can anyone help me how to do this type of Slowly Changing Dimension?
Thank you.
Hello,
Thank you for your help. I started to use DBOutputTabl, but I still have some doubts.
I’m workig with a dimension, and I only want to insert new data (comparing to a key).
For example, at my Stage:
Key | F1 | F2
1 | x | y
Then, I execute my graph and copy that to my DW.
At a second moment, I will load my Stage again. And now, my Stage is like this:
Key | F1 | F2
1 | x | y
2 | x2 | y2
So, I only want to add the second row (with Key=2).
Thank you very much for your help. I tested and everything runs perfectly.
But, I was trying to recreate this on “Free Community Edition”. And the component ‘DataIntersection’ it is not avaliable.
It is possible to control the data load, in this other version (Free Community)?
Unfortunately there is no such component in the Free Community version. However, you can create your own components.
In the newest version 4.1.0M1 of cloverETL the concept of Custom Java components has been introduced to make creating custom components easier. The components are CustomJavaReader, CustomJavaWriter, CustomJavaTransformer and CustomJavaComponent. They differ just in the predefined java code template. In this case, you can use the component CustomJavaTransformer that contains the Java code template more focused on transforming data.
regarding your question on Slowly Changing Dimension, I have created a new thread in the Cookbook section that deals with this topic. The article describes an example of ETL processes with SCD Type 1 and Type 2 designs.
{kind=link}