Hello,
I created a project using Clover and I got stuck into a specific point because I don’t know how CloverDX can handle such a scenario.
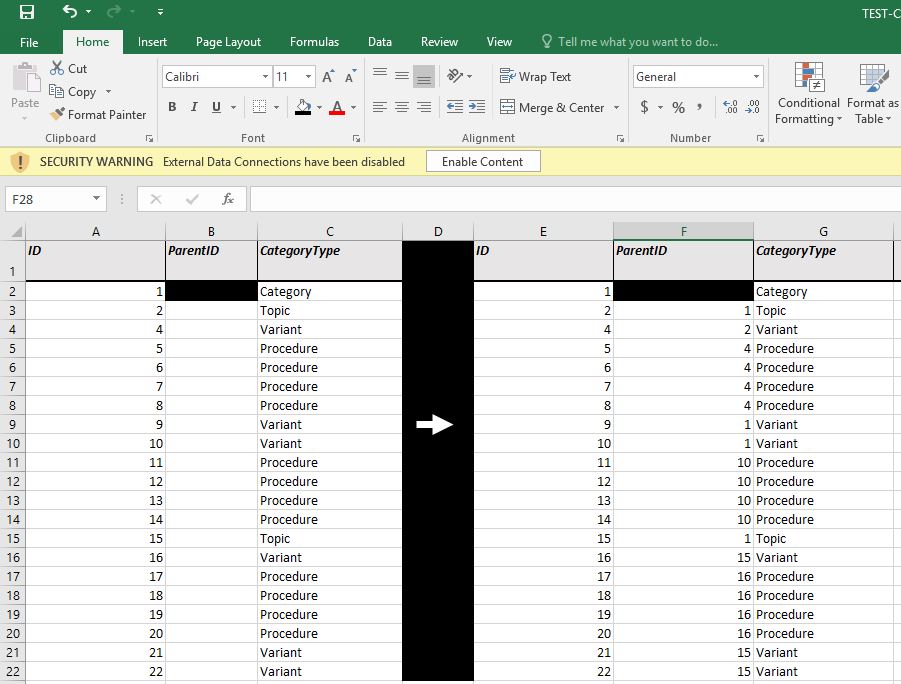
I am creating IDs from input spreadsheet and I want to create a tree by populating parent IDs.
In my input I have also Category Type that consist from Category/Topic/Variant/Procedure
The way I want to build the tree is that:
- all the Procedure IDs will have as a parent ID the Variant IDs
- all the Variant IDs will have as a parent ID the Topic IDs
- all the Topic IDs will have as a parent ID the Category IDs
- and the Category that will always be the top I will not populate anything in the Parent ID
To give a better understanding of what I am trying to do I attached a photo that shows my input into my expected output.
Populate Parent Ids.JPG
Hi Evangeloslef,
it appears that your goal can be achieved simply by using the Reformat component. I have attached an example solution to your challenge in the form of a graph. Worth noting is the following:
-
I assume that “Category” is always on top and “Topic” never forgoes its respective “Category”. “Variant” never foregoes its respective “Topic” and “Procedure” never foregoes its respective “Variant”.
-
Note the usage of 3 local variables in the Reformat component transformation mapping. The idea is that CloverDX is checking the type of record using the IF condition and whenever it finds any of the parent ones, it will assign their ID to the respective local variable.
-
Then, CloverDX would simply pull the parent_ID from the proper variable when needed.
If my assumption is not correct please elaborate on the conditions that need to be met.
Kind regards,
Vladi
Hello Gents,
I also add a little different approach => what if the ‘levels’ is unknown amount?
First i create one solution what is practically is the same as Vladi solution (what is the most cleanest and fast solution).
And below that i add another solution, what handle in theory the case of unknown (unlimited) amount of CategoryTypes (parent/child relation).
First i wondering to use some ARRAY way of solving, and also think about the Rollup.
But for curiosity i choose a ‘looks difficult’ approach: more component and less code based, and use DeDup components mainly.
I like to highlight: my solution is not so effective (especially performance wise, and so on), and may possible to do in less step, but at general it may show some DeDup usage for logical cases.
Main logic steps:
-
First i get the ‘level’ names to ‘level’ numbers, and join back.
-
Calculate for each row some ‘group_id’ (x_groupid) (to keep the same level CategoryTypes under one ‘groupid’, its later helps to find out the last row in the same group (what may the parent of some child)
-
DeDup the rows, to get only the ‘last’ rows in group, and use it later as possible ‘parent’ value
-
Join back to ‘original’ rows the possible ‘parent rows’ cases (connect by logical ‘level’) => in here we get ’ lot of not good result’ rows also, what we handle in next steps.
-
We filter out rows, where we know the joined parent cant be the correct one
-
DeDup the remained rows, to get back the ‘nearest’ parent
-
And we done.
Please see the attached Graph+Sample Excel (graph and code inside is commented in some level).
Nice, thanks for an alternative approach. Good job, Andras.
{kind=link}