Hi,
I need to go through a large csv files with over 100,000 rows, translate some lookup values from a DB before inserting them to a DB table.
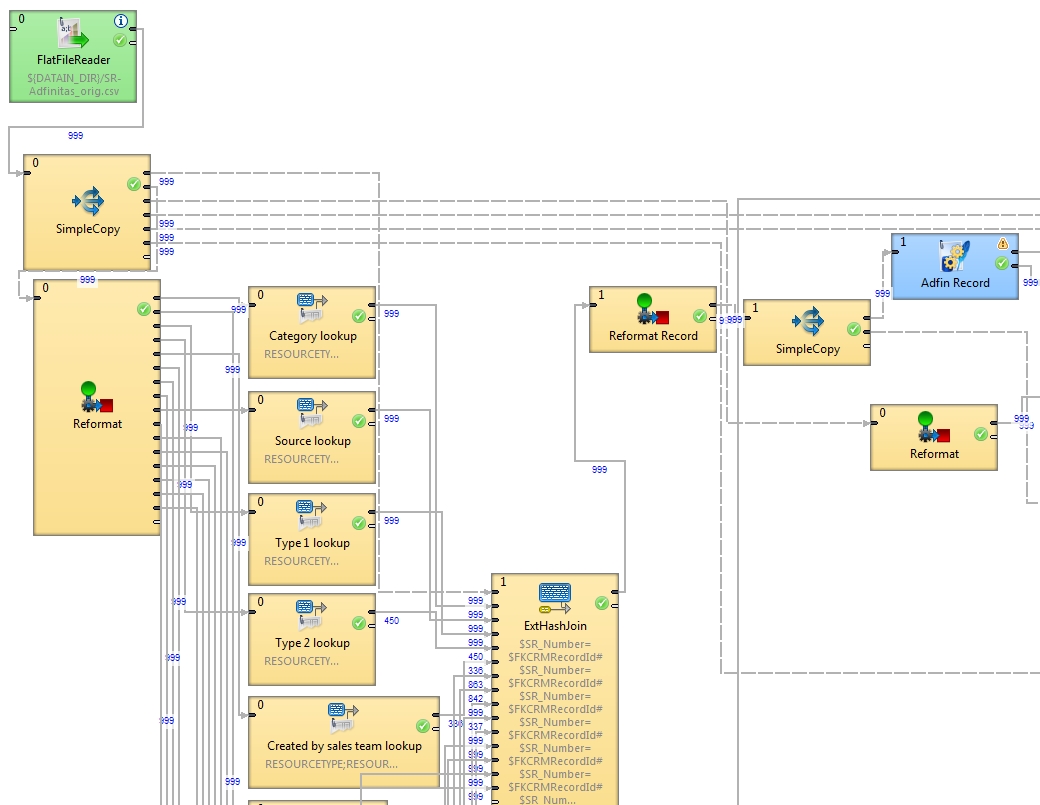
I attached a screenshot to demonstrate. Basically I used:
1. A flat file reader to read in the file
2. Followed by a number of ‘Lookup Join’ to translate some values from a DB
3. Then a ‘ExtHashJoin’ to link up all the data (since the source is not sorted)
4. Then Insert the record to a DB.
Pretty simple process and works fine for a small number of records. But when I try to import the whole file, it simply ran out of memory (increase memory allocation won’t help).
I found the ExtHashJoin is trying to wait until it joins all records before starting to insert them and that seems to be the problem, since it has to store all records in memory. I don’t really need that behaviour. Those records are all independent and can be processed in batches e.g. every 1000 rows a time but I cannot figure out a way to make it do this way.
I also tried to set different phases values but it still tries to join all values up before starting inserting the first record.
How can I tell the flat file reader to break the records down and process them in batches?
Please check my attached flow graph.
screen clover.jpg
Thanks.
Eric
Hi Eric,
there is no easy way to force the FlatFileReader component to break records down and process them in batches. However, from looking at your graph I would like to suggest a few tips that might help you resolve the memory overflow issue caused by the ExtHashJoin component.
-
As you rightly indicated, the ExtHashJoin component waits until all records (from the slave port) flow in before the joining starts. Generally, we recommend using the ExtHashJoin component if the number of slave ports records to be joined is considerably low. Since this is not the case as the number of records on the master and on the slave ports is the same, I would recommend using the ExtMergeJoin component. There is no caching (unlike ExtHashJoin) so the processing can be significantly faster. You can apply the same Master/Slave key definition and mapping for the ExtMergeJoin component as you did for the ExtHashJoin component. However, you would need to place a new ExtSort component before the SimpleCopy component in your graph. The sort key should coincide with the master key defined in the ExtMergeJoin component.
-
From the snippet of your graph, I dare to presume that the sorting order of your data does not get changed on the way from the FlatFileReader to the ExtHashJoin component whatsoever. If so there might be even a simpler approach to decrease the memory consumption. Try replacing the ExtHashJoin component with a new Combine component and apply the same mapping as you did for the ExtHashJoin component. The Combine component avoids caching the records as well and there is no need for joining by keys so the performance should be fairly good.
Best regards,
{kind=link}