Hi imriskal,
Thanks for the response. It is not always the same jobs, but the same db connection that fails.
The database is an external, third party resource hosted in Amazon, and it works 90-95% of the time. We do run a lot of jobs though, so we see this connection error often.
The error happens in different graphs, but it is about the same:
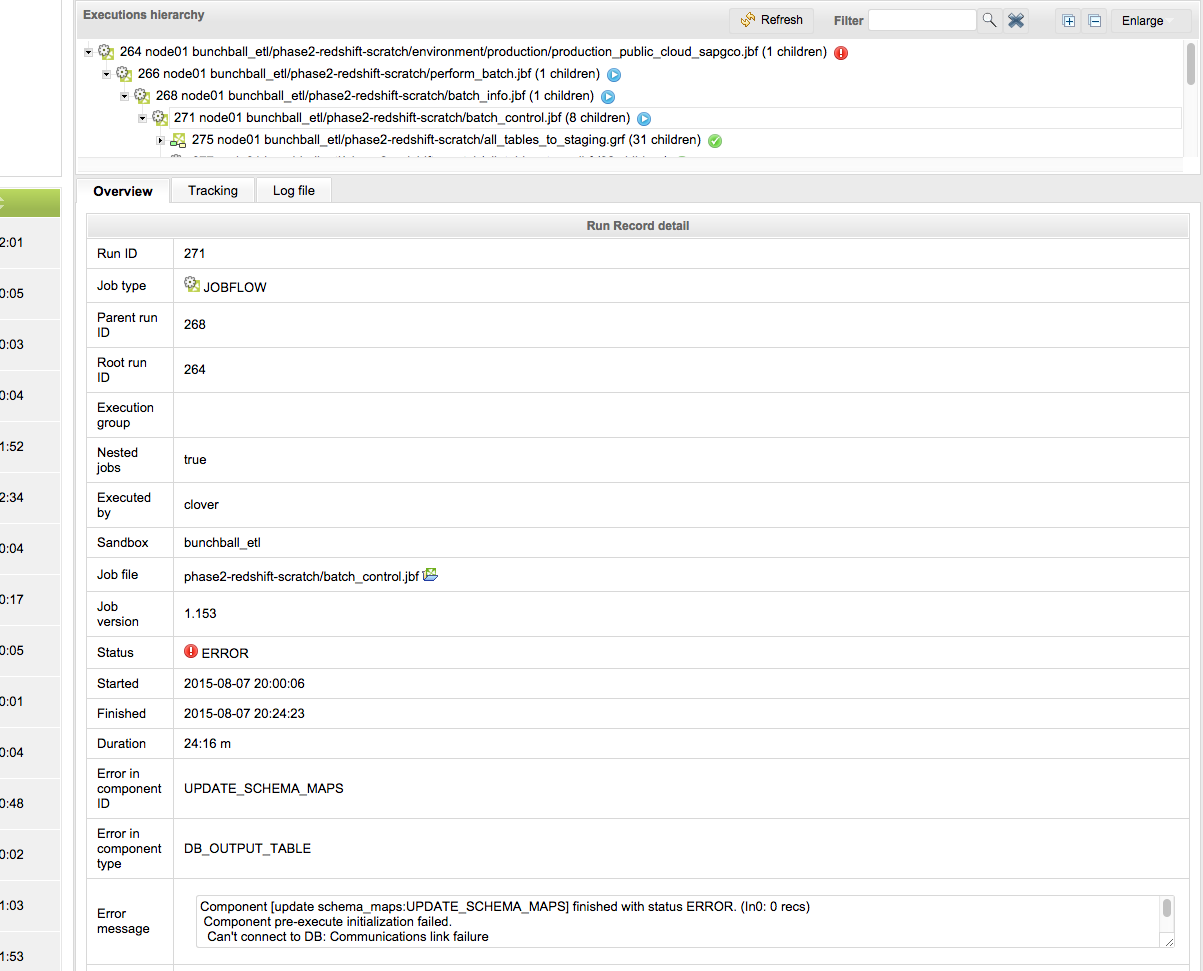
"Component [update schema_maps:UPDATE_SCHEMA_MAPS] finished with status ERROR. (In0: 0 recs)
Component pre-execute initialization failed.
Can’t connect to DB: Communications link failure
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
clover.ouramazontinstace.us-west-2.rds.amazonaws.com: Name or service not known"
We are not 100% sure yet, but it seem to happen when we have too many running graphs all hitting the same resource (from different jobs / servers).
The jobs themselves are started on a schedule, via the web admin interface, they run every 20-30 minutes, and if one of them fail, our idea was that it will be ok, since the next job will just pick up in the next run. We are using the max_running_concurrently = 1 param because our data will get messed up if the same job run as the one that run prior haven’t finished. Problem is: when one fails but cloverETL don’t mark it as red, max_running_concurrently will prevent others from start, and our ETL process gets behind.
In most cases, when we fail to connect to the amazon db, the “Communication link failure” error bubbles up correctly, the graph is marked red (as failed), and we are ok with the fail, because we have the same job running on a schedule that will continue from where the failed one left off. But eventually, one of every 100, we get one that refuses to be marked as red, and just messes everything up.
The reason we are focusing on somehow killing the rogue jobs instead of trying to make the db connection more reliable is because since it is a external resource, and it works almost all of the time, I am not sure there’s more we can do in that area. We do run A LOT of jobs, so eventually we will get exceptions in connecting, even if their success rate is 99%+
The only way we know of that we can kill those rogue jobs for sure is to restart the cloverETL server, but that sometimes end up in Initialization failure errors, which take us longer to recover. We are going to start playing with the max_graph_instance_age param to see if that will be effective in force killing those, but since the “kill” command via the admin interface don’t seem to work, our expectations are low. Attached is an image on how things look when this happens, you can see the sub-graphs green, the parent graph blue, and yet there is an error reported in red, but the status of the graph never changes from blue to red.
We are using CloverETL Server 3.5.2.12/12. Any help / advice will be appreciated. Thank you
Ramiro
Screen Shot 2015-08-10 at 10.41.08 AM.png
{kind=link}