Hi,
I have 22 DIFFERENT large(GB) csv files. I have 100,000 unique customers related information in these files.
I have created a simple graph, to read 22 csv files and than create 1 json per unique customer.
my problem is, it takes approximately 1.5 hrs for clover to write 1000 json files. If I try to process more than 2000 it throughs java out of memory exception.
Please suggest, how I can:
- I think clover JSON Writer component is slow. What should i do to improve the performance?
- what are the default memory settings, I should change for better performance?
Thanks so much!
Prashant
Dear Prashant,
For such a large data sets, I would definitely recommend increasing of memory limit. In Designer, you can do that via Run → Run Configurations… → Java memory size. Please set it as high as possible, according to your hardware. In your case, I would recommend at least 4GB or 8GB if possible.
Beside that, you can try to experiment with properties of JSONWriter, with Cache size and Cache in Memory to be more specific. Try various values and how the values affect the overall performance. See the documentation page for more details about the properties:
http://doc.cloveretl.com/documentation/ … riter.html
If nothing from above helps please send me some run logs and the graph itself.
Kind regards,
I tried following… with 64GB ram on my machine… I increase JVM -Xmx size to 16384m and set cache in memory to true. Also cache size to 8GB.
Ran into following problems:
1. The json output is incomplete.
2. The cache size on json object gave error - cant set cache size more than jvm size
3. the performance is still the same.
where should i setup the jvm size? Run Configuration → Main or Run Configuration → Aruguments
Please see my notes:
1. Could you please describe the incomplete output? Some records are missing? How many? Is the output syntactically valid?
2. Cache size has no meaning if Cache in memory is set to true, please see more details is the documentation link I provided before.
3. Could you please send your graph and graph run logs?
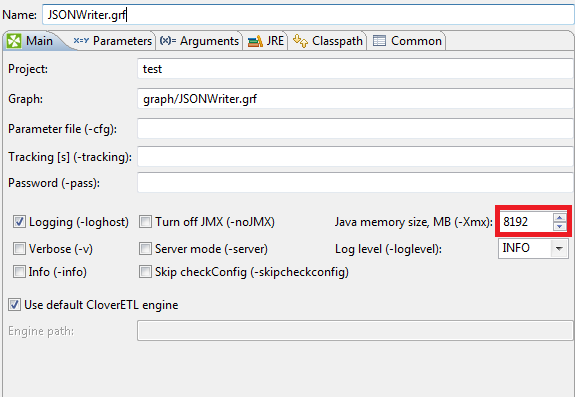
Memory settings for the graph is set in Main tab, see the screenshot.
memory.png
Kind regards,
Thanks for your reply. I replaced the universaldatareader component with parallel reader and the performance improved 5 times 
Please find answers to your questions INLINE
1. Could you please describe the incomplete output? Some records are missing? How many? Is the output syntactically valid?
>> the json structure is incomplete. syntactically invalid (missing the braces and elements, array etc…). Also, noticed it is not consistent behavior. if i reduce the number of input records, than the json are ok, otherwise 
2. Cache size has no meaning if Cache in memory is set to true, please see more details is the documentation link I provided before.
3. Could you please send your graph and graph run logs?
>> attached please find the graph.
Memory settings for the graph is set in Main tab, see the screenshot.
>> yes i have provided 32GB to the attached graph
Hello Prashant,
If the incomplete output is produced by a graph run which has ended with error then the situation is understandable, writing has ended in the middle of the process as well. But if the incomplete output is produced by a successful graph run then it is of course an error and we should search for the reason. So which situation is it, please?
Another possible reason could be not enough space in the output location. Do you think it is possible?
Regarding the memory setting, JSONWriter needs also some free space for storage of it’s internal structures so it is possible that, in the worst case, even 32GB may not be enough with 22GB of input data. In this case, please turn off the Memory in Cache again and make sure you have enough space on HDD where CloverETL stores temp files.
And the last thing, please try to replace FastSort components with ExtSort. FastSort may be extremely memory (and CPUs and HDD performance) demanding sometimes which could lead to slow performance with not enough free memory. And with such a large data input as yours, this situation is quite possible. Could you please send me some of your graph run logs so we could see where the bottleneck is?
Kind regards,
I will try adding more RAM - 64GB. I was trying to pass zip or gzip input file instead of the large csv file. But, clover throws exception like - ’ not a valid stream’ Any ideas?
i will provide you the graph with more details tomorrow.
thanks
prashant
{kind=link}