Input file has “LF” character. I am getting error message while reading the file.
Please help me to handle "LF"character if there is any way.
Hi,
This is configurable on you metadata. You just need to open up the metadata editor (double click on the metadata name in the Outline window) and select
\n
as the record delimiter - this is the escape sequence for line feed (LF). You can do this either one by one for each field separately or you can change it for all the fields at once by setting it on the Record line (the first line in the table) → Record delimiter.
\r\n
is the default one - matching CR/LF (carriage return and line feed). You can also choose any character sequence as your delimiter if need be.
If changing the delimiter doesn’t help, please attach the whole run log.
Best regards.
I have done the same thing as you mentioned but still I am getting error message.
I am using charset “ISO-8859-1” for data reader.
Here is the run log:
***************************** CloverETL Graph: *******************************
Project: Test
Graph: graph/NMStateCombined.grf
Run ID: 47
Refresh interval: 5 seconds
Connecting to CloverETL runtime …
-------------------------------- Job log: ------------------------------------
19:19:50,411 INFO [qtp1225358173-10059] *** CloverETL, (c) 2002-2017 Javlin a.s. ***
19:19:50,411 INFO [qtp1225358173-10059] Running with CloverETL version 4.5.0 build#010 compiled 14/03/2017 06:17:18
19:19:50,411 INFO [qtp1225358173-10059] Running on 8 CPU(s), OS Windows 10, architecture amd64, Java version 1.8.0_101, max available memory for JVM 582656 KB
19:19:50,411 INFO [qtp1225358173-10059] License No. : CLP1DSUNGA86554863BY
19:19:50,480 INFO [JobStarter_47] Initializing job id:1533648548601 hashCode:952500344
19:19:50,480 INFO [JobStarter_47] Checking graph configuration…
19:19:50,496 INFO [JobStarter_47] Graph configuration is valid.
19:19:50,496 INFO [JobStarter_47] Graph initialization (EE MAINT)
19:19:50,496 INFO [JobStarter_47] Initializing phase 0
19:19:50,511 INFO [JobStarter_47] Phase 0 initialized successfully.
19:19:50,511 INFO [JobStarter_47] Initializing watchdog
19:19:50,518 INFO [WatchDog_47] Job parameters:
CLOVER_USERNAME=IPUB9U1a5+brjS7/IIgV8A==
CONN_DIR=${PROJECT}/conn
DATAIN_DIR=${PROJECT}/data-in
DATAOUT_DIR=${PROJECT}/data-out
DATAOUT_PATH=${DATAOUT_DIR}
DATATMP_DIR=${PROJECT}/data-tmp
GRAPH_DIR=${PROJECT}/graph
GRAPH_FILE=graph/NMStateCombined.grf
JOBFLOW_DIR=${PROJECT}/jobflow
JOB_FILE=graph/NMStateCombined.grf
LIB_DIR=${PROJECT}/lib
LOOKUP_DIR=${PROJECT}/lookup
META_DIR=${PROJECT}/meta
NODE_ID=node01
PARENT_RUN_ID=47
PROFILE_DIR=${PROJECT}/profile
PROJECT=.
ROOT_RUN_ID=47
RUN_ID=47
SANDBOX_CODE=Test
SANDBOX_ROOT=C:/Users/e5553207/workspace Clover 4.5/Test
SEQ_DIR=${PROJECT}/seq
SUBGRAPH_DIR=${GRAPH_DIR}/subgraph
TRANS_DIR=${PROJECT}/trans
event_file_url=${DATAIN_DIR}/InputFile.csv
19:19:50,518 INFO [WatchDog_47] Runtime classpath: [file:/C:/Users/e5553207/workspace Clover 4.5/Test/trans/]
19:19:50,518 INFO [WatchDog_47] Initial dictionary content:
19:19:50,518 INFO [WatchDog_47] DictEntry:filesToDelete:string:null
19:19:50,518 INFO [WatchDog_47] DictEntry:renameTargetFile:string:null
19:19:50,518 INFO [WatchDog_47] DictEntry:renameSourceFile:string:null
19:19:50,649 INFO [WatchDog_47] Starting up all nodes in phase [0]
19:19:50,649 INFO [WatchDog_47] Successfully started all nodes in phase!
19:19:50,803 ERROR [WatchDog_47] Component [CSV Reader:CSV_READER] finished with status ERROR. (In0: 1 recs, Out0: 0 recs)
Parsing error: Unexpected record delimiter, probably record has too few fields. in record 1, field 16 (“Contribution”), metadata “InputData”; value: ‘123456789,ABCD,EFGH,19950119,20150526,727 John Ct.,Las Vegas,NJ,12345,12345,20191108,100.00,0.00\n’
19:19:50,803 ERROR [WatchDog_47] Error details:
org.jetel.exception.JetelRuntimeException: Component [CSV Reader:CSV_READER] finished with status ERROR. (In0: 1 recs, Out0: 0 recs)
at org.jetel.graph.Node.createNodeException(Node.java:636)
at org.jetel.graph.Node.run(Node.java:603)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.jetel.exception.BadDataFormatException: Parsing error: Unexpected record delimiter, probably record has too few fields. in record 1, field 16 (“Contribution”), metadata “InputData”; value: ‘123456789,ABCD,EFGH,19950119,20150526,727 John Ct.,Las Vegas,NJ,12345,12345,20191108,100.00,0.00\n’
at org.jetel.data.parser.DataParser.parsingErrorFound(DataParser.java:580)
at org.jetel.data.parser.DataParser.parseNext(DataParser.java:477)
at org.jetel.data.parser.DataParser.getNext(DataParser.java:175)
at org.jetel.util.MultiFileReader.getNext(MultiFileReader.java:439)
at org.jetel.component.DataReader.execute(DataReader.java:272)
at org.jetel.graph.Node.run(Node.java:563)
… 3 more
19:19:51,139 INFO [WatchDog_47] Execution of phase [0] finished with error - elapsed time(sec): 0
19:19:51,140 ERROR [WatchDog_47] !!! Phase finished with error - stopping graph run !!!
19:19:51,140 INFO [WatchDog_47] Final dictionary content:
19:19:51,140 INFO [WatchDog_47] DictEntry:filesToDelete:string:{value=./data-in/InputFile.csv}
19:19:51,140 INFO [WatchDog_47] DictEntry:renameTargetFile:string:null
19:19:51,140 INFO [WatchDog_47] DictEntry:renameSourceFile:string:null
19:19:51,140 INFO [WatchDog_47] -----------------------** Summary of Phases execution **---------------------
19:19:51,140 INFO [WatchDog_47] Phase# Finished Status RunTime(sec) MemoryAllocation(KB)
19:19:51,140 INFO [WatchDog_47] 0 ERROR 0 184942
19:19:51,140 INFO [WatchDog_47] ------------------------------** End of Summary **---------------------------
19:19:51,140 INFO [JobFinalizer_47] Finalization
19:19:51,140 INFO [WatchDog_47] WatchDog thread finished - total execution time: 0 (sec)
19:19:51,141 INFO [JobFinalizer_47] RunTime: 746 ms
19:19:51,141 ERROR [JobFinalizer_47]
------------------------------------------------------------------------------------------------------------------------------- Error details --------------------------------------------------------------------------------------------------------------------------------
Component [CSV Reader:CSV_READER] finished with status ERROR. (In0: 1 recs, Out0: 0 recs)
Parsing error: Unexpected record delimiter, probably record has too few fields. in record 1, field 16 (“Contribution”), metadata “InputData”; value: ‘123456789,ABCD,EFGH,19950119,20150526,727 John Ct.,Las Vegas,NJ,12345,12345,20191108,100.00,0.00\n’
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
19:19:51,141 INFO [JobFinalizer_47] Finished Status: ERROR
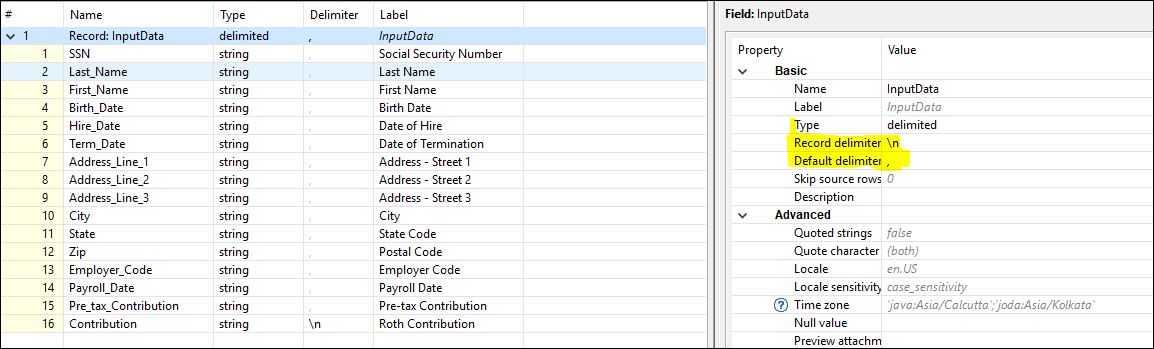
Okay, this is a different error and is not related to the record delimiter (\r\n vs. \n) but the field delimiter. It appears the fields in the file are delimited by comma, whereas the default field delimiter is pipe |. I just realized I made a mistake in my previous explanation. The record delimiter can be changed via editing the “Record delimiter” property of the Record line in the metadata editor or by editing the “Delimiter” column of the last field. On the contrary, the field delimiter can be changed via “Default delimiter” property of the Record line or by the “Delimiter” column of the Record line (both are applied to all fields without specific settings) or by changing the “Delimiter” column for each field separately except the last field. I hope it makes sense.
So if the fields in the input file are really delimited by comma, you need to change the field delimiter (Default delimiter) to comma as well.
Hope this helps.
I have same metadata setting as mentioned. But Still I am getting error while reading the file.
Please refer attached screenshot of Metadata.
{kind=link}
Okay, basically, if it’s still the same error: “Unexpected record delimiter, probably record has too few fields.”, it means there’s a mismatch in the expected number of fields and the actual number of fields coming from the input file. Can you please attach an example input file that causes this issue. I would like to see if there’s anything wrong with the file and hopefully create an example graph that would be able to read it.
Thank you in advance.
I have attached input .csv file. File has “LF” character as end of line.
Hi,
I’m not sure if you’re aware of that functionality but you can actually extract metadata from the input file. I did exactly that on your input file and it works flawlessly. Attached is an example graph that works with your file. You can test it in your environment and compare it to your graph.
Let me know if the graph works for you as well, please.
Best regards.
I don’t know what was the issue, I just removed “\n” from Delimiter column of last line of metadata and graph is working fine.
Initially I had manually entered “\n” in the Delimiter column of last line of metadata and it was showing in highlighted mode. And graph was not working. After removing “\n” from last line, “\n” is still showing there but in shadow form (not highlighted), and graph started working.
I have done this after viewing your graph. In your graph “\n” was in shadow form in the Delimiter column of last line of metadata.
I hope I am making sense what I am trying to say. Any idea why Clover behaves this way?
Thank You for help and input.
Hi,
I just found out this is a feature of the metadata configuration as per the documentation. I must admit it’s confusing and I didn’t know about this feature either. On the other hand, it might be useful for certain corner cases.
Best regards.
Thank You. Seems configuration rule.